



Introduction
The Certified Site Reliability Professional is a comprehensive validation of an engineer’s ability to manage complex, large-scale systems with a focus on reliability, scalability, and efficiency. This guide is designed for professionals navigating the evolving landscape of cloud-native engineering and platform management. As organizations move away from traditional operations toward automated, software-defined infrastructure, understanding SRE principles becomes a mandatory requirement for career progression.
In the current technology market, the shift toward DevOps and Platform Engineering has created a high demand for individuals who can bridge the gap between software development and systems operations. This certification serves as a roadmap for engineers to master the art of maintaining high availability while facilitating rapid feature deployment. By following this guide, professionals can understand how to position themselves effectively within the SRE ecosystem hosted at SREschool.
The purpose of this guide is to provide an unbiased, senior-level perspective on the value of the certification. We will explore how it fits into different career paths, from security-focused roles to data-centric operations. Whether you are a seasoned principal engineer or an aspiring systems administrator, this breakdown will help you make an informed decision about your professional development and long-term career trajectory.
What is the Certified Site Reliability Professional?
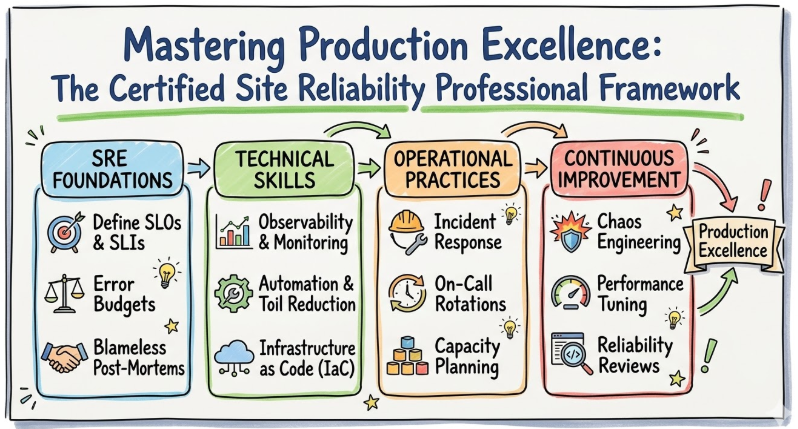
The Certified Site Reliability Professional represents a standard of excellence for engineers who specialize in the reliability of production environments. It is not merely a theoretical exercise but a validation of the practical skills required to handle high-pressure operational scenarios. The program focuses on the Google-pioneered approach to SRE, emphasizing the use of software engineering practices to solve infrastructure and operations problems.
This certification exists to bridge the gap between academic knowledge and the harsh realities of managing distributed systems. It emphasizes the importance of Service Level Objectives (SLOs), error budgets, and the reduction of manual toil through aggressive automation. In a modern enterprise, where downtime results in significant financial loss, having a certified professional ensures that the infrastructure is resilient by design.
The curriculum is built around modern engineering workflows, incorporating elements of Infrastructure as Code (IaC), continuous monitoring, and automated incident response. It aligns with enterprise practices that demand high velocity without sacrificing stability. By completing this program, engineers demonstrate their capability to design systems that are self-healing and capable of scaling dynamically with user demand.
Who Should Pursue Certified Site Reliability Professional?
Software engineers who find themselves increasingly involved in the operational aspects of their code will find this certification highly beneficial. It provides the framework necessary to move into senior SRE or Platform Engineering roles. For DevOps professionals, it offers a path to specialize in the “reliability” pillar of the DevOps loop, which is often the most challenging aspect of the software lifecycle to master.
Cloud architects and security professionals also stand to gain significantly from this track. Understanding how reliability impacts security posture and cloud costs is essential for technical leadership. Managers who oversee engineering teams should pursue this certification to better understand the metrics and methodologies that drive successful operations, allowing them to lead with more technical empathy and precision.
In both the Indian market and the global arena, the demand for SREs is outstripping the supply of qualified talent. Beginners with a strong foundation in Linux and networking can use this as a structured entry point into the world of high-scale systems. For experienced veterans, it serves as a formal validation of years of “in-the-trenches” experience, providing a recognized credential that can lead to senior staff and principal-level opportunities.
Why Certified Site Reliability Professional is Valuable and Beyond
The longevity of the SRE discipline is rooted in the fundamental need for system stability, which will never become obsolete regardless of the specific tools being used. As long as businesses rely on software to generate revenue, they will need professionals who can guarantee that software remains accessible and performant. This certification focuses on principles over specific syntax, ensuring that the knowledge remains relevant as the industry moves from VMs to containers to serverless.
Enterprise adoption of SRE practices is accelerating as companies move away from “best-effort” operations toward data-driven reliability management. By earning this certification, you demonstrate a commitment to a discipline that is central to the modern digital economy. The return on investment for your time is significant, as SRE roles consistently command some of the highest salaries in the technology sector due to the specialized nature of the work.
Furthermore, the certification helps professionals stay relevant in an era dominated by automation and artificial intelligence. While tools might change, the logic behind incident management, capacity planning, and system architecture remains constant. This program equips you with the mental models needed to adapt to new technologies quickly, ensuring that you are seen as a strategic asset to your organization rather than just a tool operator.
Certified Site Reliability Professional Certification Overview
The program is delivered via the official SREschool.com platform and is designed to cater to various stages of an engineer’s career. It is structured into distinct tiers, ranging from foundational concepts to advanced architectural strategies. The assessment approach is rigorous, combining objective testing with practical scenarios that reflect real-world production issues. This ensures that the holder of the certification is truly capable of performing SRE duties.
The ownership of the program rests with a body of industry experts who regularly update the content to reflect the latest trends in the field. Unlike certifications that focus solely on a single cloud provider, this program is designed to be cloud-agnostic, focusing on the core methodologies that apply across AWS, Azure, Google Cloud, and on-premises environments. This makes it a versatile asset for any professional regardless of their current stack.
The structure is practical, prioritizing hands-on experience and case studies over rote memorization. Candidates are expected to understand the “why” behind operational decisions, such as why a certain error budget was chosen or how a specific monitoring strategy helps reduce Mean Time to Repair (MTTR). This approach ensures that the certification holds weight in the eyes of hiring managers and technical recruiters who are looking for genuine expertise.
Certified Site Reliability Professional Certification Tracks & Levels
The certification is divided into three primary levels: Foundation, Professional, and Advanced. The Foundation level focuses on the terminology, core metrics, and the philosophical shift from traditional SysAdmin work to SRE. It is the perfect starting point for those new to the field or for stakeholders who need to understand the SRE vernacular to better collaborate with technical teams.
The Professional level dives deep into the implementation of SRE practices. It covers the technical details of building monitoring pipelines, managing distributed tracing, and implementing automated deployment strategies. This is the “workhorse” level of the certification, aimed at engineers who are responsible for the day-to-day reliability of production services. It aligns with mid-to-senior level career goals and focuses on tactical excellence.
The Advanced level is aimed at architects and technical leaders who are responsible for the reliability strategy of an entire organization. It covers complex topics like multi-region failover, disaster recovery at scale, and building an SRE culture within a large company. These levels allow for a natural career progression, enabling an engineer to grow from a contributor to a strategist over time while maintaining a consistent learning path.
Complete Certified Site Reliability Professional Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| Core SRE | Foundation | Beginners, Managers | Basic IT Knowledge | SLOs, SLIs, Toil, SRE Culture | 1st |
| Core SRE | Professional | SREs, DevOps Engineers | Linux, Scripting | Observability, Incident Management | 2nd |
| Core SRE | Advanced | Architects, Principals | 5+ Years Experience | Global Scaling, DR Strategy | 3rd |
| Automation | Professional | Automation Engineers | Python/Go, IaC | CI/CD, Automated Remediation | 2nd (Specialist) |
| Security | Professional | DevSecOps Engineers | Basic Security | Resilient Security Infrastructure | 2nd (Specialist) |
Detailed Guide for Each Certified Site Reliability Professional Certification
Certified Site Reliability Professional – Foundation
What it is
This certification validates a candidate’s understanding of the core principles and philosophy of Site Reliability Engineering. it confirms that the individual understands how to balance the need for new features with the requirement for system stability.
Who should take it
It is suitable for entry-level engineers, project managers, and product owners who need a fundamental understanding of SRE. It is also an excellent starting point for experienced developers looking to transition into operations.
Skills you’ll gain
- Understanding of Service Level Indicators (SLIs) and Service Level Objectives (SLOs).
- Knowledge of Error Budgets and how they govern deployment velocity.
- Techniques for identifying and reducing operational toil.
- Familiarity with the SRE vocabulary and team structures.
Real-world projects you should be able to do
- Define a set of meaningful SLIs for a basic web application.
- Calculate an error budget based on a desired availability percentage.
- Document a process to automate a repetitive manual task.
Preparation plan
- 7-14 days: Review the official SRE handbook and familiarize yourself with key terminology.
- 30 days: Attend a foundation workshop and practice defining metrics for sample applications.
- 60 days: Engage in peer discussions and take multiple practice exams to solidify conceptual understanding.
Common mistakes
- Focusing too much on specific tools rather than the underlying principles.
- Underestimating the importance of the cultural aspect of SRE.
- Failing to understand the mathematical relationship between availability and downtime.
Best next certification after this
- Same-track option: Certified Site Reliability Professional – Professional.
- Cross-track option: Certified DevOps Fundamental.
- Leadership option: Engineering Management Foundation.
Certified Site Reliability Professional – Professional
What it is
The Professional level validates the technical ability to implement SRE practices in a production environment. It covers the tools and methodologies required to monitor, maintain, and improve complex distributed systems.
Who should take it
This is intended for active DevOps engineers, SREs, and systems engineers who have at least two years of experience. It is for those who are responsible for the uptime of critical services.
Skills you’ll gain
- Implementation of full-stack observability (Logging, Metrics, Tracing).
- Mastering incident response and post-mortem analysis.
- Building automated deployment pipelines with integrated health checks.
- Managing infrastructure through code and configuration management.
Real-world projects you should be able to do
- Build a Prometheus and Grafana dashboard for a microservices cluster.
- Facilitate a blameless post-mortem for a simulated production outage.
- Implement a canary deployment strategy for a high-traffic service.
Preparation plan
- 7-14 days: Intensive lab work focusing on monitoring tools and alerting rules.
- 30 days: Deep dive into incident management frameworks and on-call rotations.
- 60 days: Complete a capstone project involving the automation of a complex recovery process.
Common mistakes
- Ignoring the “soft skills” required for successful incident management.
- Setting up too many alerts, leading to alert fatigue.
- Neglecting the security implications of automated infrastructure changes.
Best next certification after this
- Same-track option: Certified Site Reliability Professional – Advanced.
- Cross-track option: Certified FinOps Professional.
- Leadership option: Certified Technical Lead.
Certified Site Reliability Professional – Advanced
What it is
The Advanced certification validates the expertise required to design and manage global-scale, highly resilient systems. It focuses on high-level architecture, disaster recovery, and organizational reliability strategy.
Who should take it
Senior SREs, Principal Engineers, and Enterprise Architects who lead large technical organizations should take this. It requires significant prior experience in managing production environments at scale.
Skills you’ll gain
- Designing for multi-region and multi-cloud resilience.
- Implementing chaos engineering to discover system weaknesses.
- Strategic capacity planning and performance optimization at scale.
- Leading organizational change to adopt SRE at the enterprise level.
Real-world projects you should be able to do
- Design a disaster recovery plan that meets a 15-minute RTO for a global app.
- Execute a controlled chaos engineering experiment on a production-like environment.
- Create a long-term capacity model based on historical growth and seasonal trends.
Preparation plan
- 7-14 days: Study white papers on distributed systems and global traffic management.
- 30 days: Analyze case studies of major outages and the architectural failures behind them.
- 60 days: Architect a theoretical global system and have it reviewed by industry peers.
Common mistakes
- Over-engineering solutions for problems the organization doesn’t yet have.
- Focusing on technical fixes when the root cause is often organizational.
- Failing to account for the human element in large-scale disaster recovery.
Best next certification after this
- Same-track option: Specialized Cloud Architect certifications.
- Cross-track option: Certified DataOps Architect.
- Leadership option: CTO / VPE Leadership Program.
Choose Your Learning Path
DevOps Path
The DevOps path focuses on the integration of development and operations through continuous delivery. Candidates following this route use the SRE certification to ensure that their “Ops” side is as robust as their “Dev” side. It emphasizes the use of CI/CD pipelines to not only deliver code but to ensure that code is reliable upon arrival. This path is ideal for those who enjoy building the tools that other engineers use.
DevSecOps Path
The DevSecOps path integrates security into the heart of the SRE workflow. Professionals here learn how to make reliability and security two sides of the same coin. This involves automating security audits, implementing “security as code,” and ensuring that incident response includes security breach protocols. It is a critical path for those working in highly regulated industries like finance or healthcare.
SRE Path
The pure SRE path is for those who want to specialize exclusively in the science of reliability. This path focuses heavily on deep systems knowledge, kernel tuning, and complex distributed systems theory. It is a specialized journey that leads to roles at major tech companies where the scale of operations requires a dedicated reliability engineering team. It is the most direct application of the certification.
AIOps Path
The AIOps path explores the intersection of artificial intelligence and systems operations. Professionals in this track learn how to use machine learning models to predict outages before they happen and automate the analysis of vast amounts of log data. This is a forward-looking path that suits those with an interest in data science and automated decision-making systems.
MLOps Path
The MLOps path is specifically tailored for managing the reliability of machine learning models in production. It addresses the unique challenges of “model drift” and data pipeline failures, which are different from traditional software bugs. This path is essential for organizations that rely on AI for their core product offerings and need consistent model performance.
DataOps Path
The DataOps path applies SRE principles to data engineering and data pipelines. It focuses on ensuring data quality, availability, and low latency for analytics and reporting systems. Professionals here learn how to treat data as a product that requires its own set of SLIs and SLOs. It is a rapidly growing field as companies become more data-driven.
FinOps Path
The FinOps path combines financial accountability with the variable spend model of the cloud. By applying SRE principles, professionals learn how to optimize cloud costs without compromising on system performance or reliability. It involves creating a culture where engineering teams take ownership of their cloud usage and the associated costs, ensuring maximum value for every dollar spent.
Role → Recommended Certified Site Reliability Professional Certifications
| Role | Recommended Certifications |
| DevOps Engineer | CSRP Professional, Automation Specialist |
| SRE | CSRP Professional, CSRP Advanced |
| Platform Engineer | CSRP Professional, Infrastructure Specialist |
| Cloud Engineer | CSRP Foundation, Cloud Provider Certs |
| Security Engineer | CSRP Foundation, DevSecOps Specialist |
| Data Engineer | CSRP Foundation, DataOps Specialist |
| FinOps Practitioner | CSRP Foundation, FinOps Specialist |
| Engineering Manager | CSRP Foundation, Leadership Track |
Next Certifications to Take After Certified Site Reliability Professional
Same Track Progression
Deepening your specialization within the SRE domain involves moving toward architectural roles. After achieving the Advanced CSRP, you should look toward specialized certifications in Chaos Engineering or Advanced Observability. These credentials prove that you are not just a generalist, but a specialist in a specific niche of reliability that can solve the hardest problems in the industry.
Cross-Track Expansion
Broadening your skills is essential for becoming a well-rounded technical leader. If you have mastered SRE, the next logical step is to explore FinOps or DataOps. Understanding the financial impact of infrastructure or the complexities of data reliability makes you a much more valuable asset to the business. This cross-pollination of skills allows you to speak the language of different departments effectively.
Leadership & Management Track
For those looking to move away from hands-on keyboard work, a transition to technical leadership is the next step. Certifications in Engineering Management or CTO leadership programs build upon your technical foundation. They teach you how to manage people, budgets, and organizational strategy, using the data-driven mindset you gained from your SRE training to lead high-performing teams.
Training & Certification Support Providers for Certified Site Reliability Professional
DevOpsSchool
DevOpsSchool provides a robust framework for learning SRE concepts through interactive, instructor-led sessions. They focus on providing a hands-on environment where students can practice real-world scenarios. Their curriculum is updated frequently to include the latest industry tools and practices. With a strong presence in India, they offer both online and classroom training to cater to a wide range of professionals. Their mentorship program is highly regarded for helping students navigate the complexities of modern DevOps and SRE workflows efficiently.
Cotocus
Cotocus is known for its specialized focus on cloud-native technologies and container orchestration. They provide intensive training programs that are designed to get engineers up to speed with modern infrastructure requirements quickly. Their approach is highly practical, emphasizing lab-based learning over traditional lectures. Cotocus has built a reputation for helping organizations transform their engineering teams through targeted skill development. Their SRE-focused modules are particularly strong in areas like Kubernetes and service mesh architectures, making them a top choice for platform engineers.
Scmgalaxy
Scmgalaxy is a comprehensive community and training portal that has been supporting DevOps professionals for over a decade. They offer a wealth of free resources alongside their professional training programs, making them a go-to for continuous learning. Their SRE training tracks are built by industry veterans who bring years of practical experience to the classroom. Scmgalaxy excels at explaining the integration between traditional configuration management and modern site reliability practices. They are an excellent resource for anyone looking to understand the history and evolution of the SRE role.
BestDevOps
BestDevOps focuses on providing premium training content for senior engineers and technical architects. Their courses are designed to be challenging and thought-provoking, pushing students to think deeply about system design and reliability. They offer specialized tracks that align closely with the requirements of top-tier technology companies. The instructors at BestDevOps are often active practitioners who bring current, relevant examples of production challenges into their teaching. Their SRE program is particularly well-suited for those looking to reach the Advanced level of certification.
devsecopsschool.com
DevSecOpsSchool is the leading authority on integrating security into the SRE and DevOps lifecycles. Their training programs are essential for any engineer working in an environment where security is a top priority. They teach students how to automate security checks and build resilient systems that can withstand both operational failures and malicious attacks. Their curriculum covers a wide range of security tools and methodologies, ensuring that graduates are well-equipped to handle the security challenges of modern distributed systems. They provide a unique perspective on reliability that includes security as a core metric.
sreschool.com
SRESchool.com is the primary hub for Site Reliability Engineering education and the host of the Certified Site Reliability Professional program. They offer the most direct and comprehensive path to achieving this certification, with content tailored specifically to the exam requirements. Their platform includes a mix of documentation, video lessons, and interactive labs that cover every aspect of the SRE discipline. Because they are the host of the certification, their training materials are always perfectly aligned with the latest standards and expectations of the program.
aiopsschool.com
AIOpsSchool is dedicated to the emerging field of using artificial intelligence to enhance IT operations. Their courses teach engineers how to leverage big data and machine learning to automate the detection and resolution of system issues. For an SRE, this training is invaluable for scaling operations beyond what is possible with human intervention alone. They provide practical experience with AIOps platforms and teach the underlying data science principles required to implement these systems effectively. It is the premier destination for anyone looking to stay at the cutting edge of operational technology.
dataopsschool.com
DataOpsSchool focuses on the reliability and efficiency of data pipelines, a critical but often overlooked aspect of modern infrastructure. They apply SRE principles like SLOs and automated testing to the world of data engineering. Their training helps data professionals ensure that their analytics and ML models are built on a foundation of reliable, high-quality data. As organizations become increasingly dependent on data-driven insights, the skills taught at DataOpsSchool are becoming more vital. They provide a structured way to manage the complexities of modern data architectures at scale.
finopsschool.com
FinOpsSchool addresses the critical intersection of cloud engineering and financial management. They provide the training necessary for SREs and DevOps engineers to understand and optimize the costs associated with their infrastructure. Their program covers the cultural shift required for FinOps, as well as the technical tools used for cost monitoring and cloud waste reduction. By learning at FinOpsSchool, professionals can ensure that their pursuit of reliability is also financially sustainable. This training is essential for anyone responsible for large-scale cloud budgets in a modern enterprise environment.
Frequently Asked Questions (General)
- How difficult is the CSRP certification?
The difficulty is moderate to high, as it requires a solid understanding of both software engineering and systems operations. It is designed to test practical application rather than just memorization. - What is the typical time required to prepare?
Most professionals spend between 30 and 60 days preparing, depending on their existing experience with SRE and DevOps practices. - Are there any mandatory prerequisites for the Foundation level?
There are no formal prerequisites, but a basic understanding of Linux and how web applications work is highly recommended. - What is the ROI of getting this certification?
The ROI is high, often leading to salary increases and opportunities for more senior roles in high-growth technology companies. - In what order should I take the certifications?
The recommended order is Foundation, followed by Professional, and then either a specialization track or the Advanced level. - Is the certification recognized globally?
Yes, the CSRP is recognized by major technology firms and enterprises around the world as a valid measure of SRE expertise. - How often does the certification need to be renewed?
The certification is typically valid for two to three years, after which a renewal exam or continuing education credits are required. - Does the certification focus on a specific cloud provider?
No, the program is cloud-agnostic and focuses on principles that apply to AWS, Azure, Google Cloud, and on-premises systems. - What tools will I need to learn for the Professional level?
You should be familiar with Prometheus, Grafana, Kubernetes, and at least one Infrastructure as Code tool like Terraform. - Can I skip the Foundation level if I have experience?
While possible, it is recommended to take the Foundation exam to ensure you are familiar with the specific terminology used in the program. - Is there a community or support group for candidates?
Yes, many of the training providers listed offer forums and community groups where candidates can share tips and study materials. - What is the format of the exam?
The exams are typically online and proctored, consisting of a mix of multiple-choice questions and practical lab scenarios.
FAQs on Certified Site Reliability Professional
- How does this certification handle incident management training?
It focuses on the Incident Command System (ICS) and teaches how to manage roles like the Incident Commander, Scribe, and Communications Lead during a crisis. - Is there a focus on specific observability tools?
While the principles are tool-agnostic, the program provides deep dives into industry standards like Prometheus, Grafana, and OpenTelemetry for practical application. - Does the program cover the “human” side of SRE?
Yes, a significant portion is dedicated to cultural aspects such as blamelessness, psychological safety, and managing on-call burnout within engineering teams. - Can I skip the Foundation level?
If you have significant documented experience in an SRE role, you may be able to challenge the Professional exam directly, though Foundation is recommended for alignment. - How is “Toil” addressed in the curriculum?
The program provides specific frameworks for identifying manual, repetitive tasks and teaches strategies for automating them to ensure engineers focus on high-value work. - Are there regional variations for the certification?
The standards are global, but the support providers listed offer localized context, particularly for the high-demand tech markets in India and Southeast Asia. - What makes this certification different from vendor-specific ones?
This certification focuses on the engineering mindset and architectural patterns rather than just memorizing a specific cloud provider’s console or CLI. - Is this suitable for a System Administrator?
Yes, it is the perfect “up-skilling” path for a System Administrator who wants to transition into a more modern, software-defined operations role.
Final Thoughts: Is Certified Site Reliability Professional Worth It?
From the perspective of a career mentor, the answer is a practical yes. The industry has moved past the point where “knowing a bit of Linux” is enough to manage production systems. We are in an era of unprecedented complexity, and the SRE discipline provides the only scalable framework we have to manage that complexity. The Certified Site Reliability Professional is not just a badge for your resume; it is a structured way to acquire the mindset needed to survive and thrive in high-scale environments.
However, do not view this certification as a silver bullet. A credential alone will not fix a broken system or a toxic engineering culture. Its true value lies in the rigorous study process and the practical skills you acquire along the way. If you use this program as a roadmap to truly master the art of reliability, you will find yourself in high demand for the foreseeable future. My advice is to stay humble, keep practicing, and treat every production incident as a learning opportunity.